내 풀이 링크:https://github.com/lionkingchuchu/cs231n.git
GitHub - lionkingchuchu/cs231n: cs231n Spring 2022 Assignment
cs231n Spring 2022 Assignment. Contribute to lionkingchuchu/cs231n development by creating an account on GitHub.
github.com
이번 과제는 vanilla RNN 신경망을 사용해서 이미지와 이미지에 대한 설명이 저장된 COCO dataset을 통해 어떤 이미지를 입력받으면 이미지에 대한 설명을 적어주는 신경망 모델을 만드는 것이다.

vanilla RNN 신경망은 X가 연속적인 데이터일때 주로 사용한다. X의 데이터가 (100, 10) 이라면 100개의 X 데이터 중 한개의 데이터는 10개의 연속적인 원소들을 갖고 있을 것이다. RNN 신경망은 이 10개의 연속적인 원소를 첫번째부터 대입해 가며 h (hidden state) 를 업데이트 한다. 보이는 것과 같이 vanilla RNN의 경우 tanh 함수를 사용해 tanh(Whh x ht-1 + Wxh x xt) 로 매번 ht를 업데이트 한다. 여기서 Whh는 (이전의 h로 새로운 h를 만들기 위한 가중치), Wxh는 (현재의 x로 새로운 h를 만들기 위한 가중치)이다. 여기서 y (output)을 매번 만들수도 있고 안만들 수도 있는데, 만약 만든다면 Why (새로운 h로 y output 만들기 위한 가중치)를 사용한다. 여기서 Wxh, Whh, Why는 모델의 파라미터로 X의 데이터를 train할때 항상 같은 값을 사용한다.

먼저 COCO dataset를 다운로드 한다. train 이미지는 82783개, val 이미지는 40504개로 이루어져 있다. 특이한 점으로는 train_captions, val_captions가 이미지의 개수와 맞지 않게 400135개, 195954개이어서 의아했는데 5개의 train data를 출력해보니 한 이미지에 대해 다른 설명 데이터들이 있는 것을 확인 할 수 있다. COCO data의 설명은 한 이미지 당 약 5개의 설명을 갖고있다고 하니 그렇게 계산하면 82783 * 5 ~= 400135 개로 대략적으로 개수가 맞는 것을 알 수 있다.
train_features는 각각의 train 이미지 데이터를 VGGnet의 fc7 layer의 output으로 얻어낸 512개의 features들로 표현한 데이터이다. 실제 train, val의 이미지 데이터들을 다 가져오면 20GB가 넘기에 이렇게 feature들만 추출하여 가져와서, feature들을 captioning 하는데 사용하는 모델을 RNN을 사용하여 우리가 만들 것이다.
데이터를 보면 caption 데이터의 각 숫자가 word에 대응하는 것을 알 수 있다. 1은 <START> 로 시작을 알리고 2는 <END> 로 끝을 알리고 0 은 빈칸이다. 최대 dim이 17인것으로 보아 caption의 최대 길이는 17개의 단어로 이루어져 있을 것이다. 다음은 vanilla RNN의 한번의 step 구현이다.
def rnn_step_forward(x, prev_h, Wx, Wh, b):
next_h, cache = None, None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
xout = np.dot(x, Wx) + b
hout = np.dot(prev_h, Wh)
k = xout + hout
next_h = (np.exp(k) - np.exp(-k)) / (np.exp(k) + np.exp(-k))
cache = (x, prev_h, Wx, Wh, next_h)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return next_h, cache맨위의 사진의 식을 그대로 구현하면 구할 수 있다. (prev_h, Wh) + (x, Wx) 로 next_h 를 구할 수 있다. 그리고 당연히 weight만 있는 것이 아니라 bias도 있다. step에 대해 설명하자면 만약 X가 (100, 10)일때 RNN을 전부 수행하려면 (100,)개의 데이터를 10번 step 해야 한다.
def rnn_step_backward(dnext_h, cache):
dx, dprev_h, dWx, dWh, db = None, None, None, None, None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x, prev_h, Wx, Wh, next_h = cache
dxhout = (1 - np.square(next_h)) * dnext_h
dx = np.dot(dxhout, Wx.T)
dprev_h = np.dot(dxhout, Wh.T)
dWx = np.dot(x.T, dxhout)
dWh = np.dot(prev_h.T, dxhout)
db = np.sum(dxhout,axis = 0)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dx, dprev_h, dWx, dWh, dbbackward구현은 tanh함수의 미분을 잘 생각하여 chain rule을 사용하여 backpropagation을 구현하면 구할 수 있다. dxhout는 tanh함수를 backward로 지난 값이다.
def rnn_forward(x, h0, Wx, Wh, b):
h, cache = None, None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
h = np.zeros((x.shape[0], x.shape[1], h0.shape[1]))
cache = [0 for _ in range(x.shape[1])]
for t in range(x.shape[1]):
next_h, cache_t = rnn_step_forward(x[:,t,:], h0, Wx, Wh, b)
h0 = next_h
h[:,t,:] = h0
cache[t] = cache_t
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return h, cache다음은 위에서 step별로의 rnn_step을 모든 sequence에 대하여 한번에 계산하는 함수를 구현하는 것이다. loop를 돌며 계속해서 h0를 업데이트 해 가며 구한다. 또 모든 t의 대한 hidden state는 h에 저장해서 반환한다.
def rnn_backward(dh, cache):
dx, dh0, dWx, dWh, db = None, None, None, None, None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
N, T, H = dh.shape
D = cache[0][2].shape[0]
dx = np.zeros((N, T, D))
dWx = np.zeros((D, H))
dWh = np.zeros((H, H))
db = np.zeros((H,))
dh0 = np.zeros((N, H))
for t in range(T-1,-1,-1):
dx_t, dh0, dWx_t, dWh_t, db_t = rnn_step_backward(dh[:,t,:] + dh0, cache[t])
dx[:,t,:] += dx_t
dWx += dWx_t
dWh += dWh_t
db += db_t
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dx, dh0, dWx, dWh, dbbackward 구현은 매 t마다 아까의 rnn_step_backward함수를 통해 각각의 d값을 얻어낸 뒤 각 d에 더해서 반영해 준다. 아까 말한것처럼 매 sequence마다 같은 Wx, Wh, b를 쓰기에 매 sequence마다 d값을 더해주어야 총 gradient를 구할 수 있다.
def word_embedding_forward(x, W):
out, cache = None, None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out = W[x]
cache = (x, W)
#or
#N,T = x.shape
#V,D = W.shape
#mask = np.zeros((N*T,V))
#mask[np.arange(N*T),x.reshape([1,-1])] = 1
#out = np.dot(mask.reshape([N,T,V]), W)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return out, cache이번에는 각 caption을 indices로 표현한 데이터를 벡터로 바꾸어 주는 word_embedding 함수 구현이다. x는 (N, T) = (N개 데이터, T 단어 caption) 으로 이루어져 있고, w는 각 단어의 종류(vocabulary) 에 대응되는 가중치 이므로 (V, D) = (vocabulary 종류, RNN에 입력할 벡터 Dimension) 으로 이루어져 있다. 처음에 x 에 V 차원을 추가하여 인덱스인 곳에 1로 할당하여 (N, T, V)를 만들고 w 를 곱해서 답을 얻었는데 생각해 보니 V차원은 어차피 0과 1로만 이루어져 있기에 간단하게 W[x] 로 표현할 수 있었다.
def word_embedding_backward(dout, cache):
dW = None
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x, W = cache
dW = np.zeros_like(W)
np.add.at(dW, x, dout)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dWbackward 함수 구현은 np.add.at 함수를 사용해서 dout을 dW 중 x의 위치에만 더해서 쉽게 구할 수 있었다. 아까처럼 x의 (N, T)를 늘린 (N, T, V)차원이 1과 0으로만 이루어졌기에, 0이면 반영하지 않고 1일때만 반영하는 방식이다.
def temporal_affine_forward(x, w, b):
"""Forward pass for a temporal affine layer.
The input is a set of D-dimensional
vectors arranged into a minibatch of N timeseries, each of length T. We use
an affine function to transform each of those vectors into a new vector of
dimension M.
Inputs:
- x: Input data of shape (N, T, D)
- w: Weights of shape (D, M)
- b: Biases of shape (M,)
Returns a tuple of:
- out: Output data of shape (N, T, M)
- cache: Values needed for the backward pass
"""
N, T, D = x.shape
M = b.shape[0]
out = x.reshape(N * T, D).dot(w).reshape(N, T, M) + b
cache = x, w, b, out
return out, cache다음으로 temporal affine layer 기본적인 affine layer과 같아서 이미 구현해되어있었다. temporal_affine_layer 가 하는 일은 RNN을 통해 나온 output을 vocabulary size에 맞게 벡터화 시켜주는 것이다. 아까 word_embedding함수는 x raw data -> x_ vocab -> RNN dim 에 맞추어 주었다면, temporal affine layer함수는 반대로 RNN dim -> vocab dim으로 벡터화 시켜준다. 위에서는 M이 vocabulary 종류와 같을 것이고, 각 (N, T)에는 각 M vocab 종류마다의 점수가 저장될 것이다. 이 (N,T)를 통해 train 시간에는 이를 softmax 해주어 loss를 얻을 수 있다.
temporal_backward, temporal_softmax 함수도 이미 만들어져 있어 따로 포함시키진 않았다.
다음은 지금까지 만든 layer로 RNN classifier 구현이다.


먼저 x(features) 데이터를 통해 hidden state initialization을 한다. 그리고 각 caption에 대해 word embedding, RNN, temporal affine, temporal softmax를 통해 loss를 얻는다. 반대 방향으로 역전파하여 각각의 grads를 얻을 수 있다. 다음은 test 시간에 사용할 sample함수이다.
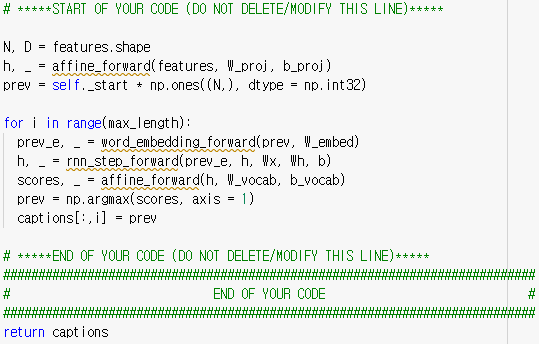
이제 수많은 train을 거쳐 optimized 된 parameter를 통해 test할 시간이다. features를 affine 해주어 hidden state initialization을 해 주고, 가장 처음에는 이전 단어가 없으니 prev를 self._start (<START>) 로 할당해준다. 그러면 vocab의 최대 길이 maxlength 까지 매 sequence 마다 hidden state 업데이트, scores을 얻는다. 여기서 나온 scores를 통해 최대 점수의 vocabulary를 통해 prev를 업데이트 해 주고, 해당 위치의 caption에도 저장해 준다. 다음 sequence에는 이전의 prev 단어를 통해 RNN을 돌리며 (h 업데이트, scores, 다음 단어 prev할당, caption 저장) 을 반복하며 caption을 완성시켜 나갈 것이다. 다 만들고 항상 그래왔듯이 train data를 overfit해보며 문제가 있는지 확인한다.
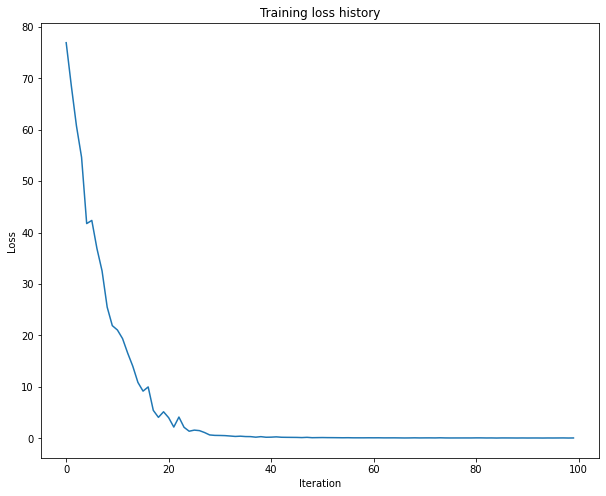
다음으로 실제로 train data, test data를 sample (test) 해보며 출력된 caption과 사진을 비교해본다.




train data에는 잘 작동했지만, val data에는 답이 하나도 맞지 않는 결과를 보여준다. 이는 train할때에는 RNN의 각 step에 맞는 정답 caption을 입력해가며 train 시켰지만, test에는 train에서 얻은 weight들을 통해 사진만 보고 만든 첫 단어를 RNN해가며 다음 단어를 이끌어내고 또 RNN하여 다음 단어를 이끌어내는 방식으로 caption을 만들기 때문이다. 그말은 만약 첫 단어가 정확하지 못했다면 다음 단어들도 아주 높은 확률로 정확하지 않을 것이다.
Inline Question 1
In our current image captioning setup, our RNN language model produces a word at every timestep as its output. However, an alternate way to pose the problem is to train the network to operate over characters (e.g. 'a', 'b', etc.) as opposed to words, so that at it every timestep, it receives the previous character as input and tries to predict the next character in the sequence. For example, the network might generate a caption like
'A', ' ', 'c', 'a', 't', ' ', 'o', 'n', ' ', 'a', ' ', 'b', 'e', 'd'
Can you describe one advantage of an image-captioning model that uses a character-level RNN? Can you also describe one disadvantage? HINT: there are several valid answers, but it might be useful to compare the parameter space of word-level and character-level models.
Your Answer: In a parameter space of word-level, we have to make a parameter for all possible word, which was 1004 in this model and it will be bigger number to make a precise prediction. While parameter in character-level we can just make a parameter of 26 alphabet letters + some signs so we can reduce the size of parameters. But using a parameter space of character-level will much harder to make a good model that predicts well since the model does not know how to make a word, it will just stack up the letters that have the best score which will mostly not make literal sense.
여기서 다음 문제는 우리가 사용한 RNN모델은 vocab종류, 즉 단어 단위로 인덱싱해가며 caption을 처리해 갔는데 만약 단어가 아닌 글자 단위로 나누어 caption을 처리하면 어떻게 결과가 달라질 것인지, 장점이 무엇이고 단점이 무엇인지 설명하는 것이다.
먼저 장점은 단어 단위의 인덱싱을 해가면 parameter가 단어의 종류만큼 있어야 하므로, 여기서는 1004개의 단어 종류를 사용하여 parameter의 크기가 매우 커졌다. 반면에 만약 글자 단위로 인덱싱한다면 글자는 고작 26개의 글자 + 공백이나 기호 를 더하면 매우 적은 parameter로도 모델을 만들 수 있기에 parameter의 크기가 매우 작아져 계산이 빨라질 것이다. 단점은 이렇게 글자 단위의 parameter를 사용하면 이전의 글자를 따라 다음 글자를 추론하는 방식으로 모델이 sample 해갈 텐데, 이렇게 하면 파라미터가 적어 정확도가 높은 모델을 만들기 어렵고, 모델이 글자로 단어를 만들기보다 점수가 높은 글자만 쌓아나가서 문학적, 문맥적으로 맞게 출력이 나오게 만들기가 매우 어려울 것이다.
'cs231n' 카테고리의 다른 글
| cs231n Assignment 3: Q2-2 (Multi-head Transformer 구현) (0) | 2023.02.26 |
|---|---|
| cs231n Assignment 3: Q2-1 (Attention 설명) (1) | 2023.02.26 |
| cs231n Assignment 2: Q6 (Saliency map, Fooling images, Class visualization 구현) (0) | 2023.02.21 |
| cs231n Assignment 2: Q5 (Pytorch 사용해보기) (0) | 2023.02.20 |
| cs231n Assignment 2: Q4 (CNN, Group Normalization 구현) (1) | 2023.02.18 |