내 풀이 링크: https://github.com/lionkingchuchu/cs231n.git
GitHub - lionkingchuchu/cs231n: cs231n Spring 2022 Assignment
cs231n Spring 2022 Assignment. Contribute to lionkingchuchu/cs231n development by creating an account on GitHub.
github.com
이번 과제는 Transformer Captioning 에 대한 과제이다. 이 Transformer 라는 모델 architecture와 Attention에 대한 상세한 개념이 2017년에 나와서 유튜브에 있는 cs231n 강의에서는 전혀 다루고 있지 않았다. 그래서 2022년 cs231n: Stanford University CS231n: Deep Learning for Computer Vision에서의 Lecture 11 slides, Transformer에 대한 논문 ([1706.03762] Attention Is All You Need (arxiv.org)), Attention에 대한 설명 (Attention? Attention! | Lil'Log (lilianweng.github.io)), transformer에 대한 설명 (The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. (jalammar.github.io)) 을 참고해 가며 attention에 대해 이해하고 과제를 진행했어야 했다.
이번에는 위에 글들을 보면서 배운 attention에 대한 개념만 설명하고 다음 포스팅에서 과제를 해보겠다.
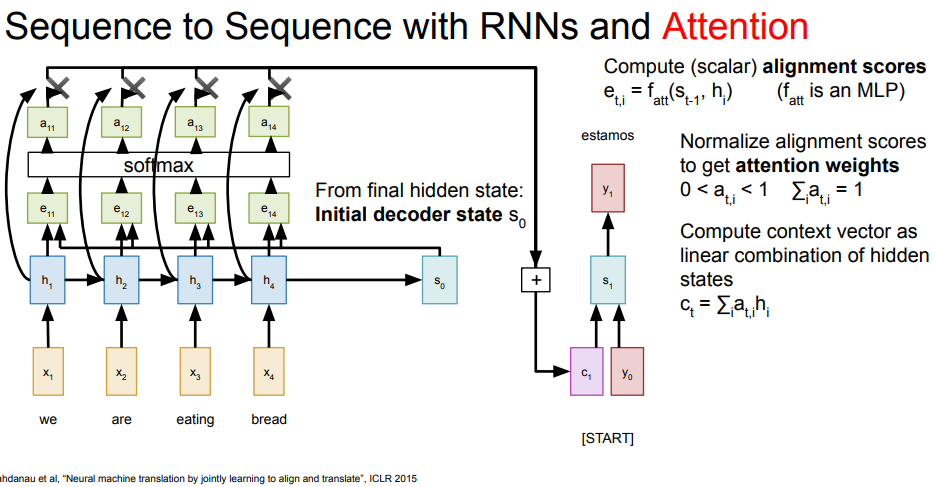
기존의 RNN을 사용한 신경망은 X데이터를 word_embed 해주고, RNN을 해주고, RNN에서 나온 context vector를 temporal_affine 해주어서 softmax loss함수를 얻어내고 test에서는 결과를 얻어냈다. 이를 seq2seq 모델이라고 하는데, seq2seq모델의 문제점은 데이터의 sequence가 길어질수록 RNN이후의 context vetor가 초반 sequence의 데이터를 기억하지 못한다는 문제가 있다.

그래서 나온 것이 attention의 추가인데 아래처럼 RNN을 마치고 나온 initial decoder state과 지금까지의 encoder hidden state를 같이 사용해서 alignment scores (아래는 MLP 신경망 사용) 를 만들고, 각 alignment scores를 통해 attention weights를 만들고 attention weights와 encorder hidden state를 곱해주고 sum해주어 context vector를 만든다. 그리고 나온 context vector와 y로 decoder hidden state 업데이트하고 다음 y를 output으로 내보낸다.
만약 attention weights 가중치들이 적절하게 모두 세팅되었다면 estamos를 만드는 c1 에서는 we에 해당하는 a11 attention weight가 다른 단어의 attention weight 들보다 더 높을 것이다. 이렇게 attention을 사용하면 context vector가 전체의 hidden state를 반영해 데이터의 sequence 전체를 볼 수 있고, 나아가 attention weight를 통해 해당 decoding에서 주의깊게 봐야할 hidden state가 어딘지도 알 수 있어 더 정확한 예측이 가능할 것이다.
다음은 Imaga Captioning을 Attention을 사용한 방법이다. features (z)로 initial hidden state (h0)을 만들고, h0과 z로 alignment scores (e) 를 만들고, alignment scores로 attention (a) 을 만들고, attention과 features로 다음 context vector (c)를 만든다.

위 과정을 General attention layer로 간략하게 표현한 것이다. input vector와 query (h) 를 통해 alignment scores (e) 를 만들고, alignment scores 로 attention (a) 을 만들고, attention과 input vector로 context vector (c)를 만든다. attention은 모든 h를 사용하므로 features의 순서에 신경쓰지 않으므로 (H,W)를 flatten해서 사용해도 된다. 과정을 수식을 제외하고 간단히 표현하면 아래와 같다. 이후 self attention layer설명때 참고하자.
z (features) -> h0 (encoder state)
(z, h0) 사용 -> e (alignment scores)
e -> a (attention)
(a, z) 사용 -> c (context vector)

아래는 self attention layer이다. 위 과정에서 x (또는 위에서는 z), input vector 는 alignment, context vector를 만드는데 두번 사용된다. 그러면 두번 사용되는 것에 raw input vector를 사용하기 보다 FCLayer를 추가시켜 준 output들을 사용하면 더 효과적이지 않을까? x를 각각 key FCLayer, value FCLayer를 통과시켜 key, value vector를 얻는다. 그리고 아까 query의 h (hidden state)도 x 를 사용해서 만들었지 않았던가? x를 query FCLayer에 통과시켜 query vector를 표현해주면 key, value, query가 각각 x로 표현 될 수 있다.
아까는 alignment에 임의의 f(h,x)를 사용했는데, alignment score function도 여러가지가 있는데 여기서는, 그리고 transformer 에서는 비율조정된 내적 (scaled dot product)을 사용한다. scaling은 alignment에 루트D를 나누어서 하는데, softmax 과정에서 scores간의 차이가 너무 크면 특정값이 지나치게 작게 나와 gradient 업데이트가 되지 않을 까봐 scaling의 목적으로 해준다. Key, Value, Query에 FCLayer를 추가했으므로 context vector 의 dimension을 FCLayer의 출력 dimension에 따라 자유롭게 조절할 수 있다.

Self Attention Layer에 대해 알았다. 근데 Attention을 사용하면 아까 말했듯이 features의 순서에 신경쓰지 않으므로 사진이나 글의 spatial data를 무시하게 된다. 그렇다면 spatial data를 유지하면서 attention을 사용할 수 있을까? 를 해결하기 위해 Positonal Encoding layer가 있다. Positional encoding은 sin과 cos함수를 이용한 p(t)함수를 이용하면 비트로 서로 다른 위치를 표현할 수 있다.

다음으로 self-attention layer를 mask해주어야 한다. 우리는 x (input vector)로 key, query를 만들었다. 그리고 key, query를 내적하여 alignment를 만들었다. 근데 문제는 내적하는 과정에서 예시로 e(1,0)을 보면 e(1,0) = k1 * q0 로 구해졌다. k1는 x1을 통해 구한 key이고 query는 x0을 통해 구한 query이다. query는 hidden state로 볼 수 있는데, 둘의 alignment score는 query 0 (h0) 이 x1, 즉 다음 step의 x (미래 x) 를 보고 구한 score가 되게 되므로 features의 순서를 반영해주기 위해서는 이런 값들의 반영을 모두 없애주어야 한다. 음의 무한대를 할당해 주어 softmax을 통해 해당 위치의 값이 0이 되게 한다.

그러면 attention에 대한 기본적인 설명이 끝났다. 뭔가 연쇄적으로 계속해서 추가되는 개념들이 많아서 이해하고 따라가는데 시간이 오래 걸렸다.
'cs231n' 카테고리의 다른 글
| cs231n Assignment 3: Q3 (GAN 구현) (0) | 2023.02.27 |
|---|---|
| cs231n Assignment 3: Q2-2 (Multi-head Transformer 구현) (0) | 2023.02.26 |
| cs231n Assignment 3: Q1 (Vanilla RNN 구현) (0) | 2023.02.25 |
| cs231n Assignment 2: Q6 (Saliency map, Fooling images, Class visualization 구현) (0) | 2023.02.21 |
| cs231n Assignment 2: Q5 (Pytorch 사용해보기) (0) | 2023.02.20 |