내 풀이 링크:https://github.com/lionkingchuchu/cs231n.git
GitHub - lionkingchuchu/cs231n: cs231n Spring 2022 Assignment
cs231n Spring 2022 Assignment. Contribute to lionkingchuchu/cs231n development by creating an account on GitHub.
github.com
SimCLR: https://arxiv.org/pdf/2002.05709.pdf

이번에는 저번 포스팅에서 설명한 SimCLR 구현 과제에 대한 풀이를 하겠다. 다시 간략하게 과정을 설명하면 기존의 사진 데이터 x에서 여러가지 방법을 사용해 data augmentation 된 x~i, x~j 쌍을 두개 만든다. 여기서 같은 사진 데이터로 만든 x~i, x~j쌍은 positive pair가 되고, 다른 사진 데이터의 각 i, j들과는 negative pair가 된다. 구한 x~i, x~j의 모든 쌍들을 이제 ResNet ( f(.) )과 같은 이미지 분류 모델을 통과시기고, 여기서 정답 class를 얻기 이전의 feature만을 추출한다. 우리가 만들 모델은 별도의 class label 없이 사진 데이터끼리의 비교를 통해 스스로 reperenstation vector를 만들는 모델을 만드는 것이므로, 이미지 분류 모델은 각 x~i, x~j들에서 feature를 추출하는 데에만 활용한다. 여기서 얻은 feature를 MLP ( g(.) )를 통과시켜 representation vector를 만들게 한다. 여기서의 MLP layer은 feature에서 좋은 representation vector를 만드는, 우리가 학습시켜야 하는 layer이다. 이후 representation vector을 만들었으면 각 벡터들의 positive pair와 negative pair끼리 비교해가며 similar score를 얻고, 이 similar scores들을 NT-Xent loss함수를 사용해 loss를 얻고 LARS optimizer로 gradient update해가며 학습시킨다.
먼저 이 과제에서는 나중에 사용할 SimCLR의 weights들을 이미 train 이미 해주었다고 한다. 직접 SimCLR의 MLP layer를 train할수 없어서 아쉽지만 아마 시간이 많이 걸려서 미리 weights들을 준 것 같다. CIFAR-10데이터를 이용해 18시간동안 train했다고 하니 정말로 시간이 많이 걸리나 보다.


처음으로 할 구현은 Data Augmentation layer 구현이다. 아래의 4개의 augmentation을 순서대로 진행하는 layer를 구현하면 된다. pytorch의 torchvision lib의 transform 함수를 보면 이미지 데이터의 augment하는 함수들이 잘 설명되어 있다. <https://pytorch.org/vision/stable/transforms.html>

조금 찾아봐야 하는것이 세번째 랜덤 color jitter인데 transforms.RandomApply()함수는 데이터 변환하는 함수를 p의 확률에 따라 적용한다. 위에 나온 color_jitter함수를 transforms.RandomApply()함수를 통해 확률로 적용시킨다.
다음은 Maximize Agreement부분에서 사용되는 similarity score를 얻기 위한 sim()함수, 그리고 구한 similarity score로 구하는 NT-Xent loss 함수 구현이다. zi, zj의 similarity는 normalized dot product로 구한다고 한다. dot product는 두 데이터 벡터에서 각각 같은 위치의 값들을 곱하여 sum해주어 구하는데, normalize를 해주었기에 그냥 각 값이 무작정 커진다고 similarity가 커지지 않고, 두 위치의 값이 유사할수록 곱이 커져 similarity가 크게 나올 것이다.
논문에서는 positive pair의 위치를 (k, k+1) 로 가정하고 식들을 설명했지만, 이 과제에서는 편의 + 쉽게 이해하기 위해 positive pair의 위치는 (k, k+N)으로 했다고 한다. x~i 가 ( 0 ~ N-1 ) 행까지 있고, x~j 가 (N ~ 2*N-1) 행까지 위치한 셈이다.

먼저 sim()함수를 구현한다. normalization은 torch.linalg.norm함수를 사용하면 쉽게 구현할 수 있다.

위에서의 sim()함수를 이용해 simclr loss의 naive한 구현이다. 루프를 사용해 먼저 l(k, K+N) 을 구한다. log 안쪽 부분의 분자와 분모를 각각 구한 뒤 log해주어 loss 1을 먼저 구하고, 다음 l(K+N, k)부분을 같은 방법으로 구해 loss2를 얻어 둘이 더해주어 완전한 loss를 만든다.

다음은 naive한 방법이 아닌 행렬 계산을 이용해 한번에 sim, loss함수 구현이다. 먼저 out_left (x~i), out_right (x~j) 를 입력으로 positive pair의 sim를 출력하는 함수 구현이다.

dot product를 1차원으로 해주어야 하는데 어렵게 생각할 필요 없이 아까 dot product는 해당 위치의 값들끼리 곱해주고 sum해주면 되기에 out_left * out_right 해주고 1차원으로 sum해주면 된다. normalization도 torch.linalg.norm을 1차원으로 적용하면 normalized dot product 구현이 된다.

다음은 2N개의 데이터 (2N, D) 를 입력으로 받아 모든 데이터끼리의 similarity score를 저장한 sim_matrix (2N, 2N)를 출력하는 함수 구현이다. 예시로 2번째 데이터와 10번째 데이터의 similarity score는 sim_matrix[2][10]에 저장되어 있을 것이다. 행렬 곱셈의 과정을 잘 생각해 보면 out, out.T를 행렬곱 (2N, D) x (D, 2N) 할 때 (0,0) 에는 (2N,D) 의 0행, (D, 2N) 0열간의 dot product가 될 것이고 (0,1)에는 (2N,D) 0행, (D, 2N) 1열간의 dot product가 될 것이다. normalization도 마찬가지로 각 행의 l2 norm (2N, 1)을 구해 norm으로 저장하고, sim_matrix 를 norm으로 행대로 나누어 주고, 열대로 나누어 주면 된다.
다음은 위에서 vectorized 방식으로 구한 sim_matrix, pos_pairs 를 사용해 simclr loss 함수 (NT-Xent) 구현이다.

먼저 시키는대로 sim_matrix에 tau를 나누고 exp해준 exponential 행렬을 만들고, mask를 사용해 같은 것끼리의 exponential (diagonal 값들) 을 없애준다 (2N, 2N-1) . 이후 NT-Xent의 분모, 분자를 각각 구해준다. 분모는 자기 자신을 제외한 sim score의 sum이므로 각 행의 sum이 될 것이다.
분자는 각 positive pair의 sim score가 될 것이다. 여기서 positive pair의 sim score는 아까 구한 sim_matrix에서 sim_matrix[k][k+N], sim_matrix[k+N][k] (0 <= k <= N-1) 에 저장되어 있을 것이므로 각각 num1, num2에 할당한 뒤 둘을 dim=0으로 붙여주면, (2N, 1)차원으로 positive pair의 sim score가 저장 될 것이다. 이를 tau로 나누어주고 exp 해주면 NT-Xent의 분자들도 완성된다. 마지막으로 -log 씌워주고 sum해주고 2N으로 나누어주면 된다.
이제 simclr에서 주요 함수의 구현이 끝났으니 본격적인 train과정을 구현해보자.

주요 input설명으로는
먼저 model은 augmented image를 통과할 f(.) + g(.) 함수, 즉 ResNet 모델 + MLP이 될 것이고,
data_loader는 우리가 구현한 data augmentation으로 사진 이미지를 변형시켜 x_i, x_j를 만들 것이고,
train_optimizer는 gradient update에 사용할 optimizer,
epoch와 epochs, batch size는 패스하고
temperature는 NT-Xent loss함수 (temperature-scaled Cross Entropy Loss) 를 구할 때의 tau이다.
그럼 이제 Model에 대해 알아보자.

Model의 forward는 ResNet f(.) 을 통과시켜 feature를 얻고, feature에서 MLP g(.)를 통과시켜 out을 얻게 된다. forward 함수는 중간값인 feature, 최종값인 out 둘 다 출력하지만 feature는 필요 없으므로 train함수에서는 out_left, out_right을 얻는 데에만 사용한다. 그렇게 얻은 out_left, out_right을 통해 loss를 얻고 optimize한다.
처음에 말했듯이 18시간동안 pretrained된 weights를 우리에게 알려주었으므로 SimCLR의 weights들을 우리가 처음부터 train 할 필요는 없다. epoch하나만 더 train 해보라고 한다. 밑에서 보면 parameter가 총 24.62M개로 매우 많은 것을 볼 수 있다 (ResNet 때문) 이를 우리가 train 하려면 매우 오래 걸릴 것이다.

만약 SimCLR을 완벽하게 train 했다면, SimCLR는 사진 데이터를 input으로 representation vector을 output으로 출력할 것이다. 그리고 이 output은 비슷한 사진들끼리 비슷한 벡터, 다른 사진들끼리는 다른 벡터를 가질 것이다. 여기서 우리는 train 과정에서 class label을 전혀 보지 않았다. 단지 여러개의 사진을 서로 비교하면서, 사진을 벡터로 분류 할 수 있게 되었다.
완벽하게 train했다면 이제 SimCLR 모델의 weights들은 건들지 말고, 뒤에 classification layer을 추가해 SimCLR의 출력 벡터를 input으로 classify 하는 layer를 붙여주고, 이 classifier layer를 train 해주면 된다.
그러면 이제 self-supervised learning을 사용하지 않은 baseline 모델과 사용한 simCLR모델의 정확도 차이를 비교해 보겠다. Classify 하는데 사용하는 layer의 구조는 아래와 같이 매우 간단하다. (2048, num_class)의 한개의 layer를 통과시켜 classify한다. 한개의 layer여도 과연 SimCLR 모델을 사용하면 높은 정확도를 가질수 있을까??

아래는 Classifier Layer을 학습시키는 train_val 함수이다.
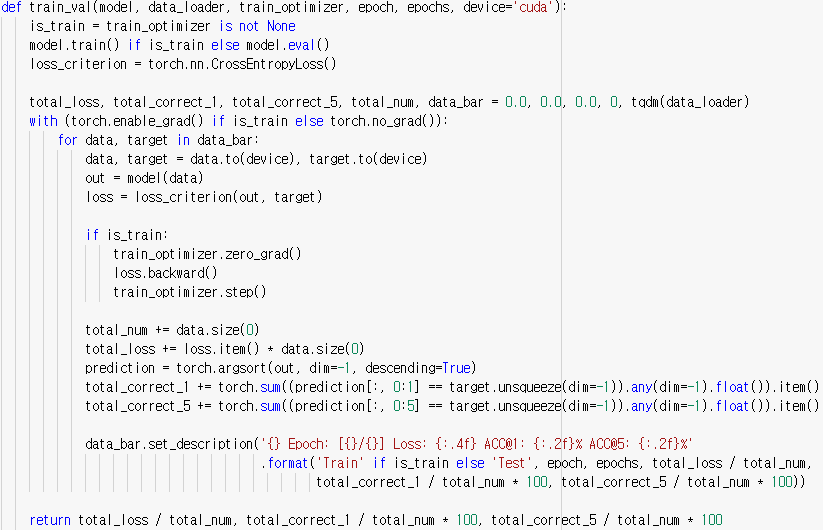
마지막 classifier layer를 train 하는 train_val함수를 보면 CrossEntropyLoss를 사용해 loss를 구하고 업데이트 하는 것을 볼 수 있다. 물론 마지막 classifier layer는 target label을 보고 학습하지만 이 layer는 representation 벡터를 class로 정렬하는 것에 불과한 layer이고, representation 벡터를 만드는 주요 모델 layer, 즉 SimCLR layer을 train할 때에는 target label을 보지 않고 학습했다는 데에 큰 의의가 있다.
먼저 baseline 모델은 projection layer ( g(.) ) 없이 feature을 바로 classifier layer 에 연결해 classify 한 것이다.

과연 SimCLR을 사용한 모델은 어떨까?


82.52 %로 매우 높은 정확도가 나왔다. train하는 과정에서 .target class label을 사용하지 않아도, 꽤 높은 정확도를 보여주는 SimCLR의 강력함을 볼 수 있다.
cs231n의 마지막 과제를 마쳤는데 과제 1에서는 신경망의 기초 layer (affine, ReLU, softmax) 등의 구현, 과제 2에서는 본격적인 이미지 처리와 정확도를 위한 convolution, normalization, dropout, 그리고 Pytorch 기초, 과제 3에서는 RNN 구현, 그리고 실제 사용되는 모델 (Transformer, GAN, SimCLR) 등의 Pytorch 구현을 해 보았다. 과제 3을 제외하고는 파이썬으로 from scratch 구현을 했는데, 이 과정에서 각 layer의 구조와 작동 원리에 대해 세세하게 알 수 있었고, 넘파이를 사용해 벡터로 문제를 해결하는 방법도 알 수 있었다. Pytorch로 모델을 구현 하는것도 사용되는 layer와 함수를 직접 구현하며 개념만이 아닌 원리까지 알 수 있어서 좋은 과제였다고 생각한다.
'cs231n' 카테고리의 다른 글
| cs231n Assignment 3: Q4-1 (Self-supervised Learning, SimCLR 설명) (1) | 2023.03.09 |
|---|---|
| cs231n Assignment 3: Q3 (GAN 구현) (0) | 2023.02.27 |
| cs231n Assignment 3: Q2-2 (Multi-head Transformer 구현) (0) | 2023.02.26 |
| cs231n Assignment 3: Q2-1 (Attention 설명) (1) | 2023.02.26 |
| cs231n Assignment 3: Q1 (Vanilla RNN 구현) (0) | 2023.02.25 |